AgentHN: Self-Editing Agents via Hypernetworks
Text-based memory breaks over long horizons and wastes the context window. We instead use hypernetworks to allow an agent to edit their own parameters at inference time. A hypernetwork (Doc-to-LoRA) converts context into LoRA adapters through a single forward pass, avoiding the lengthy training runs of SFT or RL. We show four applications — memory, personalization, skills, and self-improvement — each with an interactive replay of a captured GPU run below.
Memory
Every K turns, the oldest turns are compacted into a LoRA adapter and evicted from context. Memory persists in weights, not tokens, so the prompt stays small as the conversation grows.
Personalization
User preferences are kept in a running document and periodically internalized as a per-user LoRA profile. Profiles persist across sessions without reloading context.
Skills
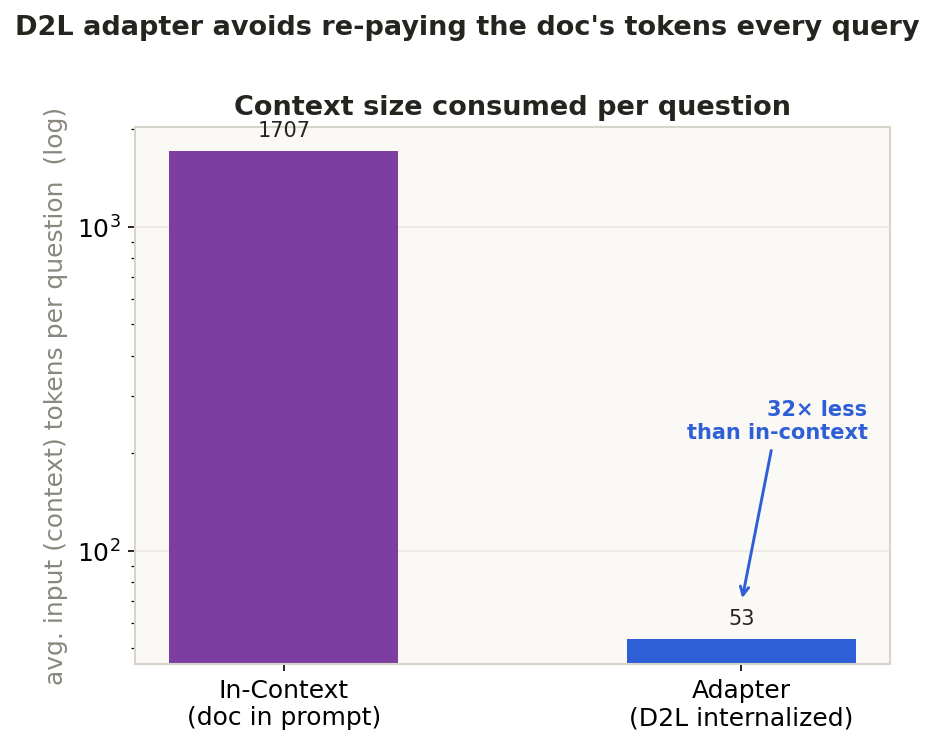
A reference doc for a skill (formulas, output-format conventions) is internalized once into a LoRA adapter. The agent recalls it straight from the weights, instead of re-paying the doc's context cost on every query.
Self-Improvement
The agent attempts a task, reflects on its mistakes, rewrites its own notes, and re-internalizes them into a fresh adapter — improving its weights over rounds with no gradient training.
One forward pass instead of a training run
SFT and RL adapt a model with long training loops. A hypernetwork instead predicts the adapter weights directly from an input, so adaptation happens in real time, mid-conversation.
See the captured runs unfold step by step
Four scenarios, replayed from captured Doc-to-LoRA runs on gemma-2-2b-it.
Constant-cost memory for long-running agents
A needle-in-a-haystack over a long trajectory: a few facts (needles) are dropped early into the conversation, then asked about at the very end. AgentHN compacts the oldest turns into a LoRA adapter every K turns — one forward pass, no training — and evicts them from context, so per-step context stays flat as the conversation grows. Baselines (markdown .md, RAG, vanilla, a trained Cartridges cache) run side by side; watch the context window and inference cost diverge.
Experiments — long-horizon memory
How AgentHN's weight-based memory stacks up against raw context, markdown notes, retrieval (RAG), and a trained Cartridges soft-prompt — on recall, context cost, scaling, and price. Every number has a script in the repo.
Doc-to-LoRA encodes a bounded document in one pass (chunk into ≤8 pieces, rank-concatenate) — good for about 4× the context window before the chunk count goes out-of-distribution and recall degrades. We instead compact repeatedly: every K turns the oldest segment becomes its own adapter in a growing store, then is evicted from context. At query time we retrieve the relevant adapter — so there's no rank-concatenation ceiling, and the horizon is unbounded.
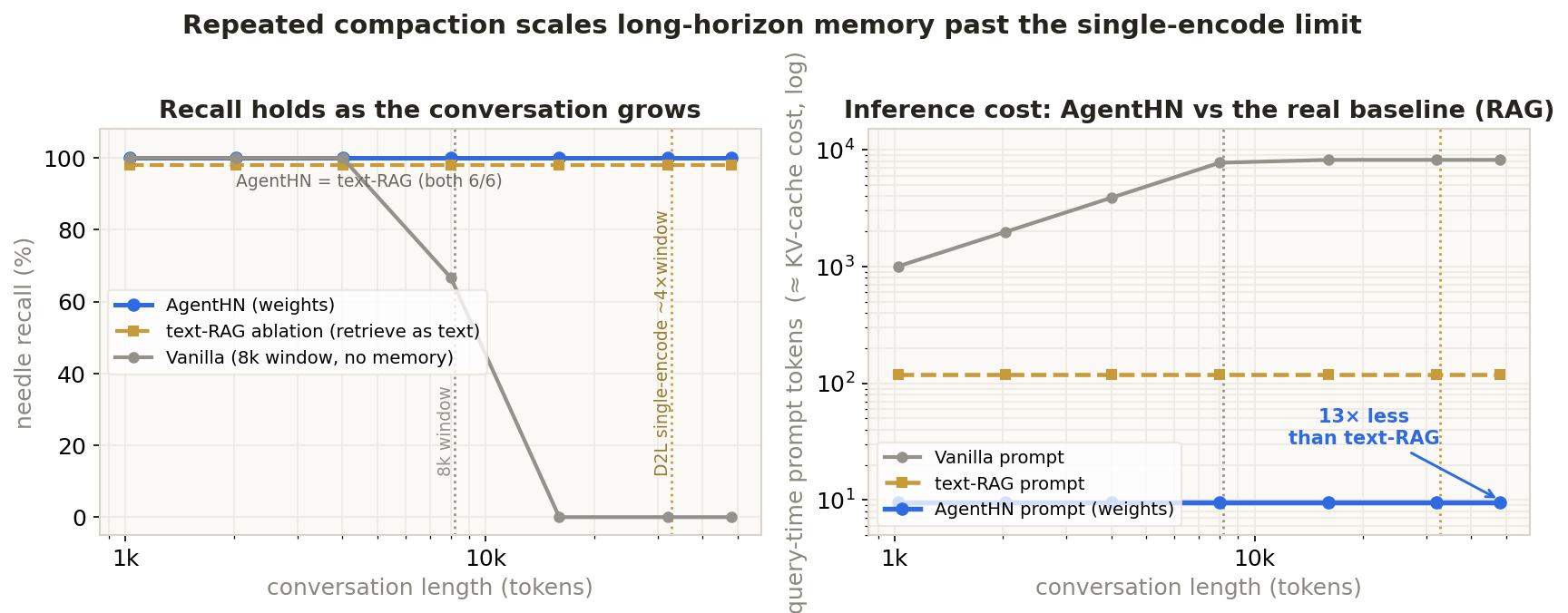
Same task, grown to 12k tokens (overflows the 8k window). We remove one component at a time and watch recall and query context. The decisive pair is the last two rows — text-RAG vs AgentHN: identical retriever, identical recall, differing only in whether the retrieved memory enters the prompt as tokens or a weight patch. That gap is exactly what the hypernetwork buys.
| Condition | What's removed | Recall | Query context | Isolates |
|---|---|---|---|---|
| vanilla | no memory | 0 / 6 | 8,498 | memory is needed |
| naive-internalize | internalize, replace (no store) | 0 / 6 | 10 | a store is needed |
| compose-all | rank-concat ALL (no retrieval) | 0 / 6 | 10 | retrieval is needed |
| text-RAG ablation | deliver retrieved chunk as text | 6 / 6 | 119 | ← removes weight-injection |
| AgentHN full | deliver retrieved chunk as LoRA | 6 / 6 | 10 | ~12× less context (recall cost quantified below) |
Beyond the curated demo: 20 random facts × 5 seeds × 5 haystack sizes (2k → 48k tokens) = 100 trials per cell, as mean ± std with Wilson 95% CIs. We also trained a real Cartridges baseline and measured it on the same task. The honest, defensible picture:
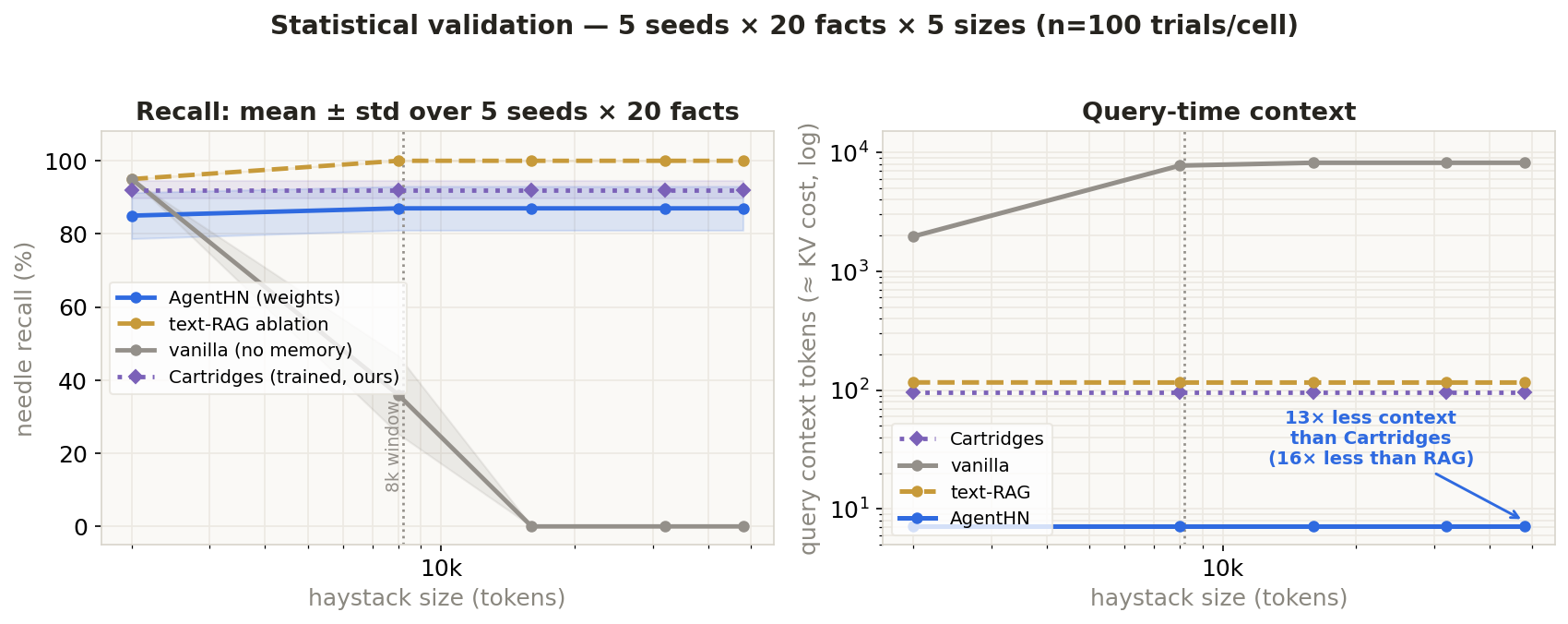
The honest framing isn't "we beat everyone" — it's which axis you optimize. Cartridges (HazyResearch) trains a KV cache offline and matches in-context quality; RAG pastes retrieved text; AgentHN predicts a LoRA in one forward pass. They differ on creation cost, online use, recall, and price:
| Method | Memory stored as | Built by | Online / streaming? | Recall | $/query (warm) |
|---|---|---|---|---|---|
| vanilla | raw text in the prompt | nothing (just append) | yes | 0% past window | 14.9µ$ |
| RAG | text chunks + index | nothing (just embed) | yes | ~100% | 0.83µ$ |
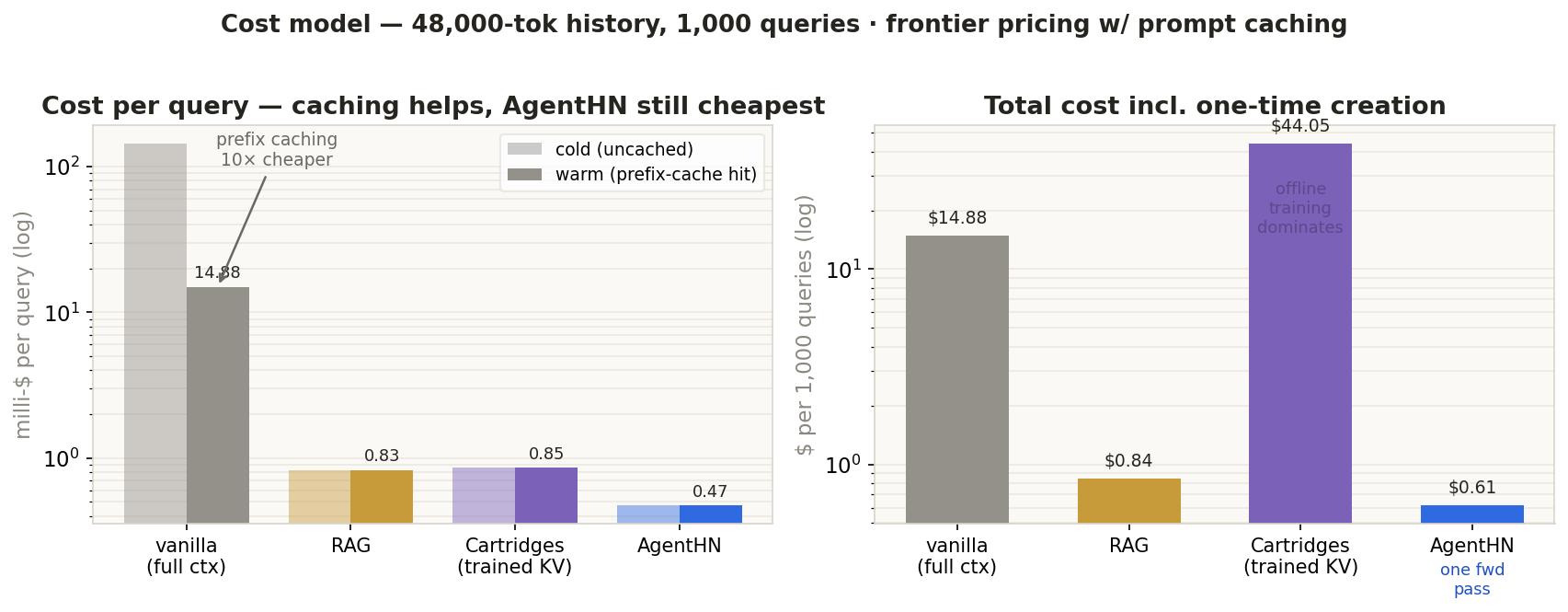
| Cartridges (HazyResearch) | trained KV cache | offline gradient training per corpus | no — batch only | 92%² (measured) | 0.85µ$ + $43 train |
| AgentHN | LoRA adapter (weights) | one forward pass per segment | yes — real-time | ~87% (lossy) | 0.47µ$ |
The takeaway: Cartridges wins on quality but trains offline and can't update mid-conversation. AgentHN is the online / real-time point — memory built in one forward pass as the agent talks, at the lowest per-query cost, paying ~13% recall for it. Different tools: streaming agent memory (AgentHN) vs a fixed corpus queried millions of times (Cartridges).
"Memory used at inference" isn't the same as cost — modern APIs let you prefix-cache a stable prompt and re-read it at ~10% price. So we price each method at representative frontier rates (input $3, cached-read $0.30, output $15 per 1M tokens) for a 48k-token history queried 1,000 times.
Experiments — skills
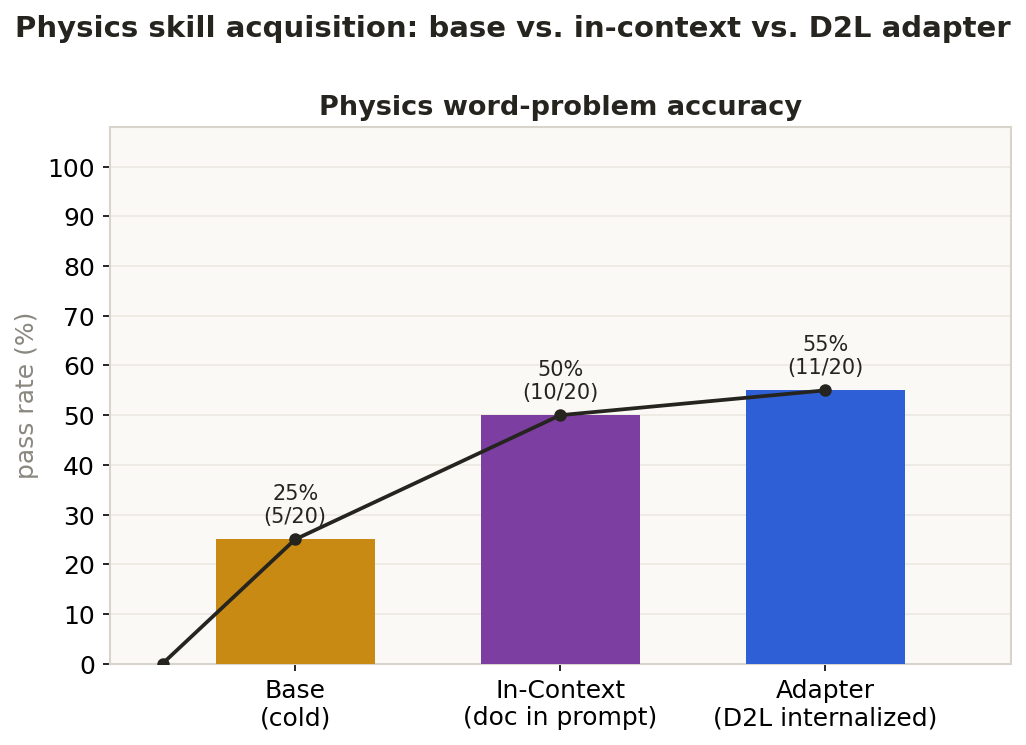
Internalizing a reference doc into a D2L LoRA adapter, measured against keeping it in the prompt — on accuracy and query-time context. Every number has a script in the repo.
The same 20 held-out physics word problems, run three ways on the bare base model. Base gets no help. In-context pastes the full Newton's-laws formula sheet into every prompt. Adapter internalizes that same doc once into a D2L LoRA — then answers with nothing in the prompt. The adapter matches (and edges out) in-context accuracy while spending ~32× less query context.